Electronique Mag - Le journal de l'électronique.
- accueil .
- abonnement .
- newsletter .
 Flux RSS .
Flux RSS . - soumissions .
- publicité .
- contacts
Flux RSS .
![]() Entretien avec Maury Wood, vice-président de la stratégie marketing chez Vicor Corporation :
Entretien avec Maury Wood, vice-président de la stratégie marketing chez Vicor Corporation :
OpenAI a lancé ChatGPT en novembre 2022. L’impact culturel découlant de la genAI (et l’impact induit par les prévisions) est phénoménal, et devrait finir par toucher tous les aspects de nos activités humaines. Du point de vue technologique, une chose est très claire : l’entraînement des modèles genAI débouchera sur les niveaux de performances les plus élevés possibles en termes de calcul, de capacités de stockage et de bande passante de réseau. La genAI incite les entreprises à atteindre des niveaux d’investissement massifs dans des domaines tels que les semiconducteurs, le matériel d’infrastructure et les logiciels, ainsi que dans le domaine de l’informatique de périphérie. Ces investissements devraient s’étendre à des appareils IA embarqués pour les véhicules, les bâtiments d’habitation et les lieux de travail.
Le revers de la médaille de cette poussée d’innovation est l’augmentation en flèche de l’utilisation de l’énergie dans les centres de données en nuage qui hébergent l’entraînement de l’IA générative et les activités d’inférencement, pour lesquels les prévisions sont très sombres. Le New York Times a récemment publié un article expliquant que « dans les scénarios intermédiaires, d’ici 2027, les serveurs IA pourraient consommer entre 85 et 134 térawattheures (TWh) par an. Cette consommation est similaire à celle de l’Argentine, des Pays-Bas ou de la Suède sur une année, et représente 0,5 % de la consommation électrique mondiale. » L’IA générative présente donc un défi majeur et urgent sur le plan de la consommation énergétique, qui est en totale contradiction avec les objectifs sociétaux de réduction des émissions de gaz à effet de serre et la neutralité carbone.
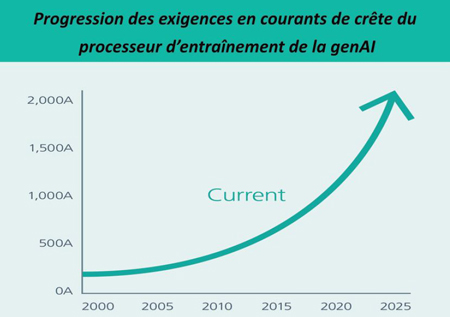
Les processeurs d’entraînement de l’IA générative utilisent un nombre pharamineux de transistors (soit 100 milliards au bas mot) dans des technologies avancées comme des micropuces CMOS de 4 nm, qui subissent des pertes de courant pendant leur fonctionnement. Bien que la tension d’alimentation de ces transistors soit très basse, de l’ordre de 0,7 VDD, la demande de courant continu peut être de l’ordre de 1000 A ou plus, équivalant à une puissance continue (aussi connue sous le nom d’enveloppe thermique) de 700 W. La demande en courant de crête peut atteindre les 2000 A, ce qui équivaut à une puissance crête de 1400 W ou plus sur de courtes durées. L’inférence genAI utilise bien moins de puissance. De manière générale, le coût énergétique de l’inférence équivaut à peu près à la racine carrée du coût énergétique de l’entraînement d’un même grand modèle de langage (LLM).
Ce problème est lié au fait que la demande de courant électrique est très transitoire, en fonction de la charge algorithmique du processeur d’entraînement. En d’autres termes, à mesure que la charge de tâches du modèle de réseau neuronal augmente ou diminue, les exigences de courant varient énormément, de l’ordre de 2000 A par microseconde. De plus, afin d’éviter d’endommager les transistors pendant ces évènements transitoires fréquents, tout dépassement supérieur ou inférieur de la tension d’alimentation doit être limité à moins de 10 % (ou 0,07 V à 0,7 VDD). Cela pose un problème de taille pour les architectures de distribution de l’alimentation traditionnelles.
Figure 1 L’alimentation et l’efficacité énergétique sont devenues les plus gros défis des systèmes informatiques à grande échelle. Le marché a connu une augmentation impressionnante de la consommation des processeurs avec l’avènement des ASIC et des GPU traitant des fonctions IA complexes. La consommation des baies modulaires a également augmenté en conséquence, les capacités IA étant utilisées sur les déploiements d’applications d’inférence et d’apprentissage à grande échelle :
Ensuite, la zone des puces nues des processeurs d’entraînement est grande, de l’ordre de 800 mm2, voire plus. Afin d’éviter d’endommager les transistors et les problèmes de fiabilité sur le long terme, la tension d’alimentation minimum doit être maintenue dans toute la surface de puce en silicium. Les architectures de distribution d’alimentation traditionnelles, avec alimentation distribuée à partir des quatre bords du boîtier du processeur genAI, doivent typiquement maintenir une tension de 0,75 V en périphérie de la puce nue afin de garantir 0,7 V au centre de la puce. Ces 0,05 V supplémentaires viennent s’ajouter à la dissipation de puissance globale.
Jusqu’à très récemment, les centres de données utilisaient une distribution de l’alimentation 12 VDC. Vicor, depuis les 10 dernières années, recommande d’utiliser une alimentation 48 VDC dans les racks des centres de données, car (grâce à la loi d’Ohm) plus la tension est grande, plus les pertes de puissance sont faibles dans les conducteurs dotés d’une résistance électrique non nulle. L’adoption d’une alimentation 48 VDC pour des applications informatiques plus performantes a connu une croissance importante dans les spécifications Open Rack normalisées par le projet Open Compute Project. Sur les premières architectures de distribution d’alimentation destinées à l’IA générative, cette tension d’alimentation nominale de 48 VDC était convertie en une tension de bus intermédiaire dans le module accélérateur, ce courant DC intermédiaire alimentant souvent des régulateurs de tension trans-inductance multi-phases (TLVR) ; cette approche possède des limites matérielles en termes d’évolutivité et de densité de courant.
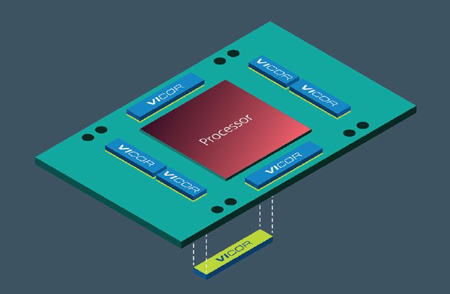
L’espace disponible sur la carte électronique des modules accélérateurs (AM) utilisés par les processeurs d’entraînement genAI est très limité, ce qui signifie que les sous-systèmes de distribution de l’alimentation pour ces processeurs doivent afficher une densité de puissance (W/mm2) et une densité de courant (A/mm2) très élevées. Les alimentations traditionnelles ne peuvent tout simplement pas atteindre la densité de puissance et de courant requises pour fournir le courant nécessaire et pouvoir être installées dans l’espace disponible de la carte électronique. Comme dit précédemment, les composants de puissance pour les processeurs d’entraînement de genAI doivent respecter les exigences sur le plan des performances dynamiques causées par les transitoires dus aux variations de charge. Une fois encore, les approches conventionnelles de distribution de l’alimentation ne sont pas adaptées pour ces exigences, en particulier car les processeurs d’entraînement de genAI nécessitent environ 3 mF de capacité de découplage aussi près que possible du boîtier du processeur.
Figure 2. Module accélérateur de genAI conceptuel montrant le processeur genAI et la compatibilité avec des mémoires HBM (mémoires haute-vitesse empilées) utilisant un boîtier à micropuces :

De plus, les composants dans une architecture de distribution de l’alimentation genAI doivent être dotés d’excellentes capacités de gestion thermique. Que le système genAI soit refroidi par un liquide ou par l’air, les composants de puissance doivent posséder une conductivité thermique élevée ainsi qu’un boîtier pouvant supporter des niveaux extraordinaires de cycles thermiques tout au long de leur durée de vie.
Les modules d’accélérateur genAI récents utilisent une architecture d’alimentation factorisée, avec des convertisseurs de point de charge utilisant la multiplication de courant, tels que ceux inventés par Vicor.
L’une des approches importantes pour réduire la consommation énergétique de la genAI, tout en améliorant la qualité de la distribution de l’alimentation, est liée au placement physique des composants de puissance du point de charge. En déplaçant les composants de puissance de l’étage final depuis un placement latéral vers un placement vertical, directement en-dessous du processeur genAI, on réduit la quantité de puissance dissipée dans la carte électronique. Avec une densité de courant d’environ 3 A/mm2, le multiplicateur de courant du point de charge peut partager l’espace très réduit sous le processeur d’entraînement genAI.
La puissance thermique de la carte électronique peutêtre diminuée car l’impédance localisée du réseau de distribution d’alimentation, placé verticalement, est diminuée par un facteur d’au moins 20 par rapport à un placement latéral des composants de puissance. De plus, la qualité de la distribution de l’alimentation augmente car la distribution d’alimentation verticale (VPD, Vertical Power Delivery) permet également une distribution de l’alimentation (VDD) bien régulée et uniforme sur toute la surface de la puce du processeur. Dans une architecture VPD, il peut y avoir 50 mV de variation de tension d’alimentation éliminés par rapport à une solution de point de charge placée de façon latérale, comme cela est habituel. Multiplié par 1000 A ou plus, on arrive à une économie potentielle de 50 W, voire plus.
Actuellement, les plus gros superordinateurs d’entraînement genAI déploient environ 20 000 modules accélérateurs. Chose étonnante, d’après Nvidia, GPT-3 de OpenAI, avec ses 175 milliards de paramètres, nécessite 300 zettaFLOPS (soit 1021 opérations à virgule flottante par seconde), ce qui équivaut à 300 000 milliards de milliards d’opérations mathématiques au cours de l’ensemble du cycle d’entraînement du modèle. Les dimensions de ces modèles ne vont faire qu’augmenter, étant donné qu’on développe actuellement des modèles de réseau neuronal avec plusieurs milliers de milliards de paramètres.
Figure 3 : Module accélérateur montrant le placement des composants de puissance placés latéralement puis verticalement pour minimiser les pertes de PDN :
Vicor estime qu’une architecture VPD factorisée peut économiser environ 100 watts par module accélérateur par rapport à la distribution de l’alimentation latérale traditionnelle (TLVR). Il convient d’ailleurs de garder à l’esprit que les superordinateurs d’IA sont alimentés essentiellement en continu (en d’autres termes, ils ne sont jamais éteints). En faisant une projection raisonnable du nombre de centre de données genAI en fonctionnement dans le monde d’ici 2027, Vicor estime une économie accumulée en térawatts équivalente à plusieurs milliards de dollars de coût d’énergie électrique et de plusieurs millions de tonnes de réduction des émissions annuelles de CO2 (en fonction du mix d’énergie renouvelable utilisé) et ce en continu.
Figure 4 : Vicor a fourni les convertisseurs DC-DC de point de charge avec la plus forte densité de courant depuis plus de 10 ans sur quatre générations de produits Cette architecture de distribution de l’alimentation innovante est associée à la topologie de circuit SAC™ (Sine Amplitude Converter) à la pointe de la technologie, qui utilise les méthodes de commutation au passage à zéro de la tension et du courant ZVS et ZCS afin de minimiser le bruit de commutation ainsi que les émissions parasites rayonnées et maximiser l’efficacité de conversion DC-DC. La commutation MOSFET à haute fréquence réduit les dimensions physiques des modules Vicor à haut degré d’intégration :

La régulation de la tension par abaissement et modulée en largeur d’impulsion (PWM) multi-phase peut être conceptualisée en tant que moyenne de courant, comme si on créait de l’eau tiède à l’aide d’un flux dynamique mélangeant de l’eau chaude (courant de crête maximal) et de l’eau froide (pas de courant). L’architecture FPA (Factorized Power Architecture™) de Vicor est fondamentalement différente et peut être conceptualisée comme une division de tension très efficace produisant une multiplication de courant. Les composants ChiP™, qui sont des multiplicateurs de courant modulaires, sont compatibles avec l’agencement de la carte électronique et permettent d’atteindre un large panel de niveaux de distribution de courant, le tout sans nécessiter beaucoup de travail de réingénierie.
Ces éléments de conception sont associés à des composants et boîtiers avancés pour résoudre les problèmes de distribution du courant dans les applications IA/HPC de nouvelle génération.
Les principaux fabricants de semiconducteurs, tels que TSMC, ont dévoilé leur feuille de route pour les 2 ou 3 prochains noeuds de processus (2 nm, 1,6 nm) utilisant des innovations CMOS telles que des transistors nanofeuille ou à nanofils GAA (à grille enveloppante). Ces améliorations concernant les paramètres physiques des composants ainsi que l’accélération de l’utilisation de boîtiers à micropuces continueront d’engendrer des niveaux de courant de plus en plus élevés pour les processeurs genAI. Du côté du développement des algorithmes, il y a fort à parier que les principaux développeurs de grands modèles de langage (LLM), tels que OpenAI, Microsoft, Google, Meta et Amazon vont accélérer les choses avec des modèles de réseaux neuronaux dotés de plusieurs milliers de milliards de paramètres, qui exigeront des capacités de calcul, de stockage et de bande passante de communication réseau jamais atteintes auparavant.
L’intelligence artificielle générative, sans aucun doute, sera l’application la plus énergivore et la plus problématique au niveau de la gestion thermique dans le monde informatique moderne. Vicor continuera d’innover pour répondre à la demande exponentielle en distribution d’énergie sur ce nouveau segment plein d’opportunités.



